TensorFlow* is an end-to-end machine learning platform and a widely used framework for production AI development and deployment, demanding efficient utilization of computational resources. To take full advantage of Intel® architectures and extract maximum performance, the TensorFlow framework has been optimized using Intel® oneAPI Deep Neural Network Library (oneDNN) primitives, a popular performance library for deep learning applications. Intel collaborates with Google* to upstream most optimizations into the stock distribution of TensorFlow, with the newest features being released earlier as an extension.
This article introduces Intel® Advanced Matrix Extensions (Intel® AMX), the built-in AI accelerator engine in 4th Gen Intel® Xeon® processors, and highlights how it can help accelerate AI training and inference performance using TensorFlow.
Intel® AMX in 4th Gen Intel® Xeon® Scalable processors
4th Gen Intel Xeon processors are designed to deliver increased performance, power-efficient computing, and stronger security, while also being optimized for overall total cost of ownership. These processors expand the reach of CPUs for AI workloads.
Intel AMX is a built-in accelerator found on each 4th Gen Intel Xeon processor core, and it helps accelerate deep learning training and inference workloads. Intel AMX architecture consists of two main components:
- Tiles - These are new, expandable 2D register files which are 1kB in size.
- TMUL (Tile Matrix Multiply) - These are the instructions which operate on the tiles to perform matrix-multiply computations for AI.
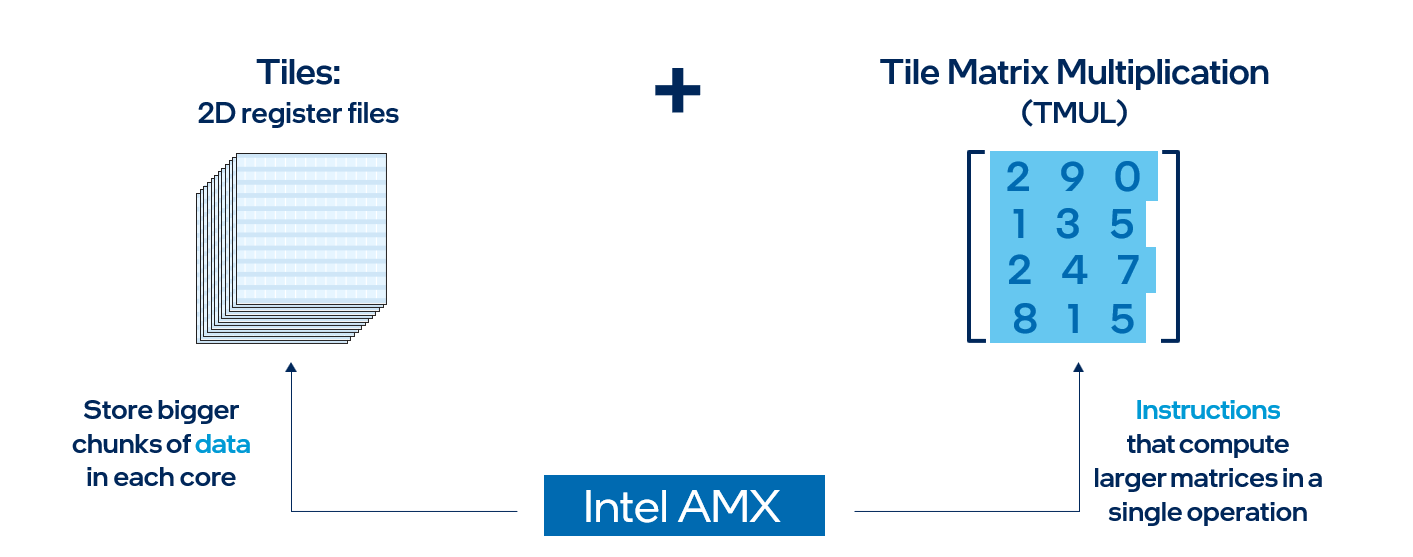
In simple terms, Intel AMX will store larger chunks of data in each core and then compute larger matrices in a single operation. Intel AMX only supports BF16 and INT8 data types, whereas FP32 data types are still supported through Intel® Advanced Vector Extensions 512 (Intel® AVX-512) instructions as found in 3rd Gen Intel Xeon processors. Intel AMX accelerates deep learning workloads such as recommender systems, natural language processing, and image detection. Classical machine learning workloads which use tabular data will use existing Intel AVX-512 instructions. Many deep learning workloads are mixed precision, and 4th Gen Intel Xeon processors can seamlessly transition between Intel AMX and Intel AVX-512 to run code using the most efficient instruction set.
So … What is Mixed Precision Learning?
This is a technique for training a large neural network in which the model's parameters are stored in datatypes of different precision (most commonly floating point 16 and floating point 32) to allow it to run faster and use less memory.
Most models today use the single precision floating-point (FP32) data type, which requires 32 bits of memory. There are, however, two lower-precision data types, float16 and bfloat16 (BF16), which each require only 16 bits of memory. Bfloat16 is a floating-point format that occupies 16 bits of computer memory but represents the approximate dynamic range of 32-bit floating-point numbers. Bfloat16 format is as follows:
- 1 bit - sign,
- 8 bits - exponent,
- 7 bits - fraction.
The comparison between float16, float32 and bfloat16 is shown in the figure:

TensorFlow Optimizations from Intel
Intel® Optimization for TensorFlow* are based on TensorFlow and built with support for oneDNN. They are available as part of the Intel® AI Analytics Toolkit. (Check out the installation guide to learn more on how to install them.)
Starting with TensorFlow 2.9, developers can take advantage of oneDNN optimizations automatically. For TensorFlow 2.5 through 2.8, the optimizations can be enabled by setting the environment variable, TF_ENABLE_ONEDNN_OPTS=1.
How to Enable Intel® AMX bfloat16 Mixed Precision Learning on a TensorFlow Model
The first step is to check if Intel AMX is enabled on your hardware. On the bash terminal, enter the following command:
cat /proc/cpuinfo
Alternatively, you can use:
lscpu | grep amx
Check the “flags” section for amx_bf16 and amx_int8. If you do not see them, consider upgrading to Linux* kernel 5.17 or newer. Your output should look something like this:

The official TensorFlow release supports Keras mixed precision feature from TensorFlow v2.9. Intel Optimizations for TensorFlow support this feature from TensorFlow v2.4.
The user can add bfloat16 mixed precision learning to an existing TensorFlow model before the entire process of learning starts by adding one line of code:
tf.config.optimizer.set_experimental_options({'auto_mixed_precision_onednn_bfloat16':True})
Remember to set the environment variable responsible for limiting the processor features of oneDNN before executing the TensorFlow model learning process. This should be added at the beginning when running a program with model learning,
ONEDNN_MAX_CPU_ISA=AMX_BF16
This will set the instruction set architecture at the level that supports Intel AMX with both INT8 and bfloat16 if the processor supports those operations. It is important to note that ONEDNN_MAX_CPU_ISA is set for the maximum supported architecture by default.
NOTE: The best improvement in the performance results will be visible on the matrix-heavy workflows.
Enable BF16 without Intel AMX:
os.environ["ONEDNN_MAX_CPU_ISA"] = "AVX512_BF16"
tf.config.optimizer.set_experimental_options({'auto_mixed_precision_onednn_bfloat16':True})
Enable BF16 with Intel AMX:
os.environ["ONEDNN_MAX_CPU_ISA"] = "AMX_BF16"
tf.config.optimizer.set_experimental_options({'auto_mixed_precision_onednn_bfloat16':True})
Training and Inference Optimizations with Intel AMX
Training
Intel Optimizations for TensorFlow enhance stock TensorFlow for performance boost on Intel® hardware. For example, newer optimizations include Intel® AVX-512 Vector Neural Network Instructions (AVX512 VNNI) and Intel AMX. This code sample shows how to train a DistilBERT model using the Disaster Tweet Classification dataset with Intel Optimizations for TensorFlow.
The Disaster Tweet Classification dataset is for binary classification tasks, which helps in predicting one of the two possible outcomes. The dataset contains over 11,000 tweets associated with disaster keywords such as "crash", "quarantine", and "bush fires" as well as the location and keyword itself. The dataset contains 5 columns; we are only concerned about the "test" column that contains the tweet data and the "target" column that shows whether the given tweet is a disaster or not.
The following steps are implemented in the code sample:
- Verify if user’s hardware supports Intel AMX, and then load the Disaster Tweet Classification dataset.
- Enable Intel AMX.
- Train a Hugging Face DistilBERT model to predict the label of tweets. During runtime, BF16 and Intel AMX are controlled with a config setting 'auto_mixed_precision_onednn_bfloat16' and an environment variable ONEDNN_MAX_CPU_ISA, respectively.
- The training time with and without Intel AMX and BF16 are measured and compared.
Try out the code sample on the Linux environment and Jupyter* notebook.
Inference
This code sample showcases how TensorFlow models can benefit from Intel AMX on inference. It uses a ResNet50v1.5 model pre-trained on the TensorFlow Flower dataset (221 MB), an image dataset containing a large set of images of flowers with 5 possible class labels.
The following steps are implemented in the code sample:
- Verify if user’s hardware supports Intel AMX.
- Enable Intel AMX and show performance improvements without affecting inference accuracy.
- Load the TensorFlow flower dataset and pre-trained TensorFlow Hub's ResNet50v1.5 model. During runtime, BF16 and Intel AMX are controlled with a config setting 'auto_mixed_precision_onednn_bfloat16' and an environment variable ONEDNN_MAX_CPU_ISA, respectively.
- The inference time with and without Intel AMX and BF16 are measured and compared.
Try out the code sample on the Linux environment and on the Intel® Developer Cloud.
Watch
Watch the video to learn more about enhancing deep learning workloads on the latest Intel® Xeon processors.
What’s Next?
Get started with TensorFlow Optimizations from Intel today and accelerate your TensorFlow training and inference performance with oneDNN features on 4th Gen Intel Xeon Scalable processor using Intel AMX. Try out this advanced code sample that shows the usage and performance comparison of model training process with and without Intel AMX bfloat16 mixed precision learning. In this sample, the users can learn about Transformer block for text classification using the IMBD dataset and how to modify the code to use mixed precision learning with bfloat16.
We encourage you to also check out and incorporate Intel’s other AI/ML Framework optimizations and end-to-end portfolio of tools into your AI workflow and learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel’s AI Software Portfolio to help you prepare, build, deploy, and scale your AI solutions.
For more details about the new 4th Gen Intel Xeon Scalable processors, visit Intel's AI Solution Platform portal where you can learn how Intel is empowering developers to run end-to-end AI pipelines on these powerful CPUs.