Many computing workloads in science, finance, enterprise, and communications rely on advanced math libraries to efficiently handle linear algebra (BLAS, LAPACK, SPARSE), vector math, fourier transforms, random number generation, and even solvers for linear equations or analysis.
This article focuses on modifying your GPU-targeted source code to use oneMKL’s SYCL API instead of CUDA*.
Before we get too far into the mapping of SYCL and CUDA syntax as well as function APIs of oneMKL and cuBLAS, etc., let us talk a little bit about oneMKL software architecture as it relates to execution on GPUs.
oneMKL Software Architecture
Shorthand for the Intel® oneAPI Math Kernel Library, oneMKL is a complete and comprehensive package of math functions and solvers. (Figure 1)
It not only is optimized for Intel® CPUs, it also supports computation offload to GPUs via OpenMP* and SYCL. This allows oneMKL to take advantage of GPU architecture, which favors small, highly parallel execution kernels. oneMKLs key functionality is directly enabled for Intel® GPU offload.
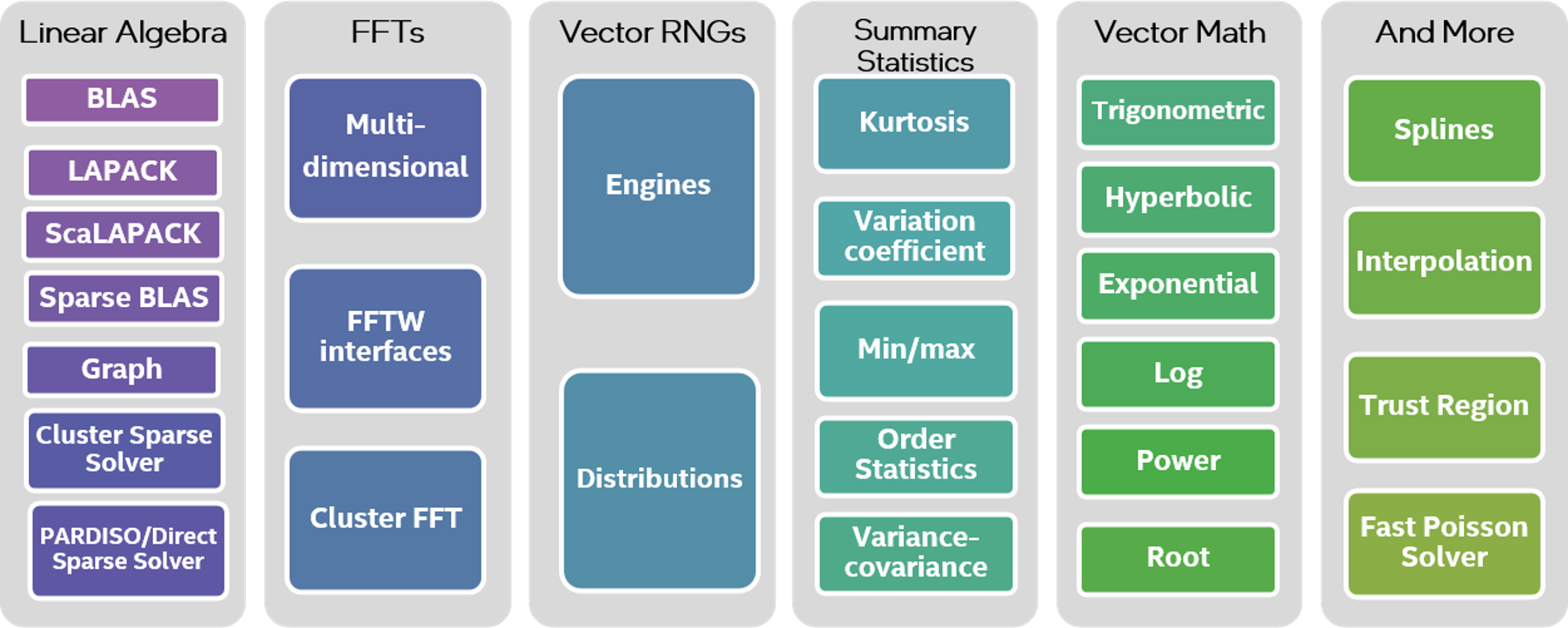
Figure 1. Intel® oneAPI Math Kernel Library Function Domain
oneMKL is provided as a free binary-only distribution. One key part of oneMKL however is not only free, but also available in source.
The SYCL API of oneMKL is open source and part of the oneAPI specification. This opens it up to being used on a wide variety of computational devices: CPUs, GPUs, FPGAs, and other accelerators.
The functionality included in the oneAPI spec is subdivided into the following domains:
- Dense Linear Algebra
- Sparse Linear Algebra
- Discrete Fourier Transforms
- Random Number Generators
- Vector Math
oneMKL GPU Offload Model
The General Purpose GPU (GPGPU) compute model consists of a host connected to one or more compute devices. Each compute device consists of many GPU Compute Engines (CE), also known as Execution Units (EU) or Xe Vector Engines (XVE). A host program and a set of kernels execute within the context set by the host. The host interacts with these kernels through a command queue.
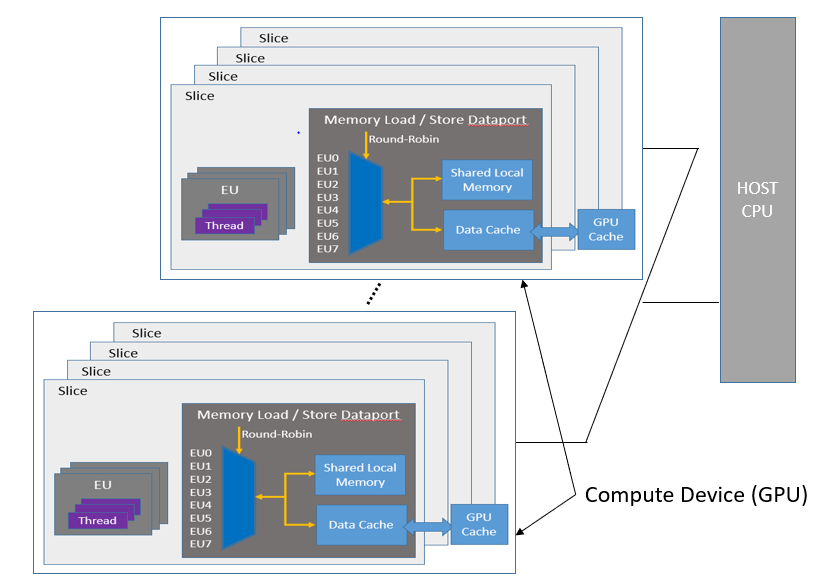
Figure 2. GPU Execution Model Overview
When a kernel-enqueue command submits a kernel for execution, the command defines an N-dimensional index space. A kernel-instance consists of the kernel, the argument values associated with the kernel, and the parameters that define the index space. When a compute device executes a kernel-instance, the kernel function executes for each point in the defined index space or N-dimensional range.
Synchronization can also occur at the command level, where the synchronization can happen between commands in host command-queues. In this mode, one command can depend on execution points in another command or multiple commands.
Other types of synchronization based on memory-order constraints inside a program include Atomics and Fences. These synchronization types control how a memory operation of any particular work-item is made visible to another, which offers micro-level synchronization points in the data-parallel compute model.
oneMKL directly takes advantage of this basic execution model, which is implemented as part of Intel® Graphics Compute Runtime for oneAPI Level Zero and OpenCL™ Driver.
oneMKL SYCL API Basics
Although oneMKL supports automatic GPU offload dispatch with OpenMP pragmas, we’re going to focus on its support for SYCL queues.
SYCL is a royalty-free, cross-platform abstraction layer that enables code for heterogeneous and offload processors to be written using ISO C++ or newer. It provides APIs and abstractions to find devices (e.g. CPUs, GPUs, FPGAs) on which code can be executed and to manage data resources and code execution on those devices.
Being open-source and part of the oneAPI spec, the oneMKL SYCL API provides the perfect vehicle for migrating CUDA proprietary library function APIs to an open standard.
oneMKL uses C++ namespaces to organize routines by mathematical domain. All oneMKL objects and routines are contained within the oneapi::mkl base namespace. The individual oneMKL domains use a secondary namespace layer as follows:
|
namespace |
oneMKL domain or content |
|---|---|
|
oneapi::mkl |
oneMKL base namespace, contains general oneMKL data types, objects, exceptions, and routines. |
|
oneapi::mkl::blas |
Dense linear algebra routines from BLAS and BLAS-like extensions. The oneapi::mkl::blas namespace should contain two namespaces, column_major and row_major, to support both matrix layouts. |
|
oneapi::mkl::lapack |
Dense linear algebra routines from LAPACK and LAPACK-like extensions. |
|
oneapi::mkl::sparse |
Sparse linear algebra routines from Sparse BLAS and Sparse Solvers. |
|
oneapi::mkl::dft |
Discrete and fast Fourier transformations. |
|
oneapi::mkl::rng |
Random number generator routines. |
|
oneapi::mkl::vm |
Vector mathematics routines, e.g., trigonometric, exponential functions acting on elements of a vector. |
oneMKL class-based APIs, such as those in the RNG and DFT domains, require a sycl::queue as an argument to the constructor or another setup routine. The execution requirements for computational routines from the previous section also apply to computational class methods.
To assign a target GPU device and control device usage, a sycl::device instance can be assigned. Such a device instance can then be partitioned into subdevices, if supported by the underlying device architecture.
The oneMKL SYCL API is designed to allow asynchronous execution of computational routines; this facilitates concurrent usage of multiple devices in the system. Each computational routine enqueues work to be performed on the selected device and may (but is not required to) return before execution completes.
sycl::buffer objects automatically manage synchronization between kernel launches linked by a data dependency (either read-after-write, write-after-write, or write-after-read). oneMKL routines are not required to perform any additional synchronization of sycl::buffer arguments.
When Unified Shared Memory (USM) pointers are used as input to, or output from, a oneMKL routine, it becomes the calling application’s responsibility to manage possible asynchronicity. To help the calling application, all oneMKL routines with at least one USM pointer argument also take an optional reference to a list of input events, of type std::vector<sycl::event>, and have a return value of type sycl::event representing computation completion:
sycl::event mkl::domain::routine(..., std::vector<sycl::event> &in_events = {});
All oneMKL functions are host thread safe.
oneMKL SYCL API Source Code
The oneMKL SYCL API source code is available on the oneAPI GitHub repository. It is under continuous active development. Backend mapping and wrappers for equivalent CUDA, AMD ROCm* and SYCL implementation for the domains BLAS, DFT, LAPACK, and RND are provided as well:
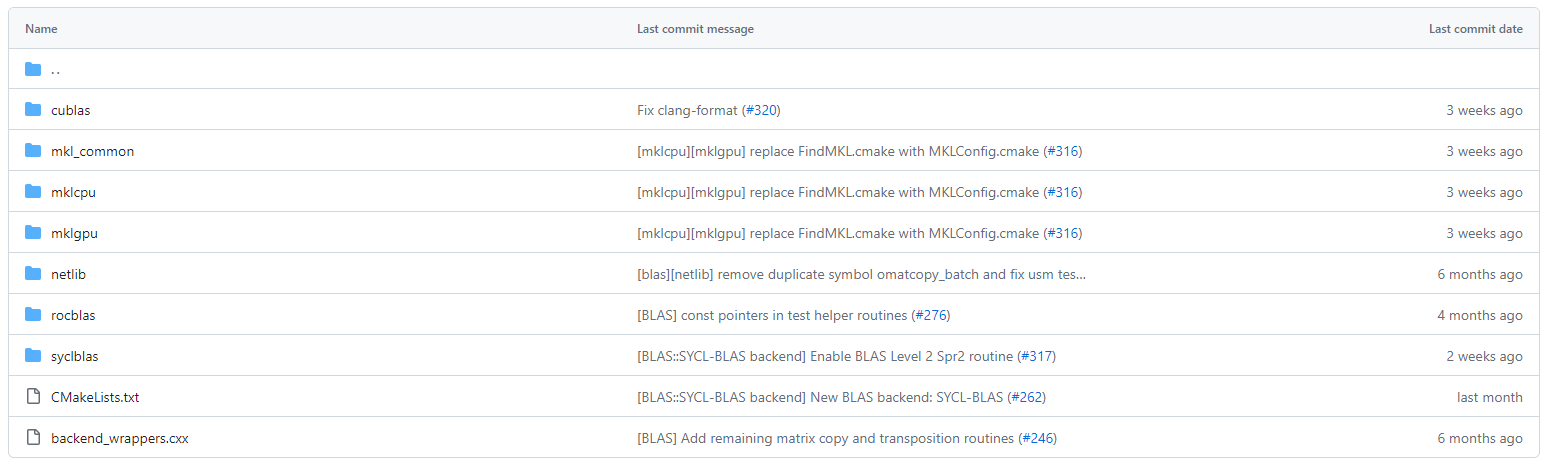
Figure 3. Available oneMKL BLAS Compatibility Backends
This open, backend architecture is what enables the oneMKL SYCL API to be applicable to a wide range of offload devices, including (but not limited to) Intel CPUs, GPUs, and accelerators.
For the complete function table in each domain you can reference the respective function_table.hpp header file:
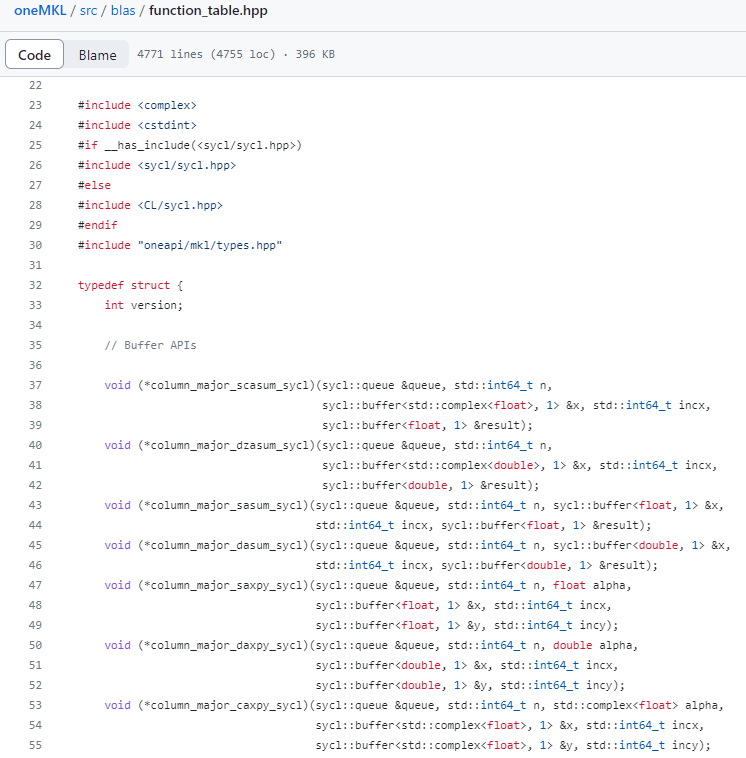
Figure 4. oneMKL BLAS Function Table Header File
Figure 5. oneMKL FFT Function Table Header File
CUDA Compatibility and Library Wrappers
To get a detailed perspective on how oneMKL functionality maps to a specific backend, you can simply go to the specific backend directory of interest and inspect the respective {backend}_wrappers.cpp file.
Figure 6. oneMKL - cuBLAS Compatibility Backend File Listing
In the cuBLAS* example in Figure 6, the file in question is cublas_wrappers.cpp.
The actual mapping implementation that you will find in a corresponding header includes files called onemkl_{domain}_cu{domain}.hpp and onemkl_{domain}_cu{domain}.hxx.
As before, we are using cuBLAS as the reference for our repository source screenshot in Figure 7. That said, the very same applies for cuFFT*, cuSolver* / LAPACK, and cuRAND*.

Figure 7. oneMKLBLAS - cuBLAS Compatibility Function Headers
On the dedicated Migrate from CUDA* to C++ with SYCL* webpage as well as the oneAPI GitHub Code Samples repository, you can find a range of source code examples that talk specifically about how to migrate different types of applications from CUDA to SYCL.
In the next paragraph let us take a closer look at one of these examples.
The migration of BLAS routines from CUDA to SYCL based on Nvidia’s own cuBLAS Library - APIs Examples, is a really good place to start.
CUDA-to-SYCL Migration
Intel and oneAPI provide streamlined tools for CUDA-to-SYCL migration, thus simplifying heterogeneous compute for math functions that still support CUDA-compatible backends and proprietary NVIDIA hardware while simultaneously freeing your code to run on multi-vendor hardware.
The Migrate from CUDA to C++ with SYCL page provides a common hub for all technical information regarding the use of available automated migration tools:
The page also includes many guided CUDA-to-SYCL code examples.
Most interesting for a deeper understanding of migrating CUDA library code to oneMKL are the following:
- Migrating the MonteCarloMultiGPU from CUDA* to SYCL* (Source Code) provides a guided example for cuRAND to oneMKL and SYCL migration.
- Guided cuBLAS Examples for SYCL Migration provides a similarly detailed reference for migration of linear algebra and GEMM routines.
cuBLAS Migration Code Sample
Let us have a closer look at the migration of the cuBLAS Library - APIs Examples in the NVIDIA/CUDA Library GitHub repository.
The samples source code (SYCL) is migrated from CUDA for offloading computations to a GPU/CPU. The sample demonstrates how to:
- migrate code to SYCL
- optimize the migration steps
- improve processing time
The source files for each of the cuBLAS samples show the usage of oneMKL cuBLAS routines. All are basic programs containing the usage of a single function.
This sample contains two sets of sources in the following folders:
|
Folder Name |
Description |
|---|---|
|
01_sycl_dpct_output |
Contains output of Intel DPC++ Compatibility Tool used to migrate SYCL-compliant code from CUDA code. |
|
02_sycl_dpct_migrated |
Contains SYCL to CUDA migrated code generated by using the Intel DPC++ Compatibility Tool with the manual changes implemented to make the code fully functional. |
The functions are classified into three levels of difficulty. There are 52 samples:
- Level 1 samples (14 samples)
- Level 2 samples (23)
- Level 3 samples (15)
Build the cuBLAS Migration Sample
Note: If you have not already done so, set up your CLI environment by sourcing the setvars script in the root of your oneAPI installation.
Linux*:
• For system wide installations: . /opt/intel/oneapi/setvars.sh
• For private installations: . ~/intel/oneapi/setvars.sh
• For non-POSIX shells, like csh, use the following command:
bash -c 'source <install-dir>/setvars.sh ; exec csh'
For more information on configuring environment variables, see Use the setvars Script with Linux* or macOS*.
- On your Linux* shell, change to the sample directory.
- Build the samples.
By default, this command sequence builds the version of the source code in the 02_sycl_dpct_migrated folder.$ mkdir build $ cd build $ cmake .. $ make - Run the cuBLAS Migration sample.
Run the programs on a CPU or GPU. Each sample uses a default device, which in most cases is a GPU.
• Run the samples in the 02_sycl_dpct_migrated folder.
• $ make run_amax - Example Output:
[ 0%] Building CXX object 02_sycl_dpct_migrated/Level-1/CMakeFiles/amax.dir/amax.cpp.o [100%] Linking CXX executable amax [100%] Built target amax A 1.00 2.00 3.00 4.00 ===== result 4 =====
Code Inspection
Upon completion, this example will give you a good representation of the flow of code migration for cuBLAS function calls to oneMKL.
You can have a close look at the resulting migrated code for all the included examples at this source location (02_sycl_dpct_migrated).
A typical conversion will look similar to the example for SGEMM in Figure 8:

Figure 8. cuBLAS to oneMKL call conversion for GEMM
Scriptable CUDA-to-oneMKL Migration
We covered the oneMKL API SYCL architecture, including how to identify exactly which cuBLAS, cuFFT, cuRAND, cuSOLVER, cuSparse, or other CUDA math library function maps to oneMKL using the relevant oneMKL backend header files.
There is a clearly discernable pattern regarding the functionality mapping and the syntax differences between CUDA libraries and oneMKL. Once you are familiar with it, even manual code migration for specialized workloads and tuning of migrated code will become routine and scriptable.
The compatibility mapping is evolving fast, so it is worthwhile to check the GitHub repository frequently.
SYCLomatic as well as the Intel DPC++ Compatibility Tool are your friends and helpers when it comes to quickly migrating CUDA code to SYCL.
The Migrate from CUDA to C++ with SYCL page let’s you find all migration resources even beyond oneMKL and performance libraries easily.
Additional Resources
- oneAPI Specification Documentation for oneMKL
- oneAPI Math Kernel Library (oneMKL) Interfaces
- oneMKL - Data Parallel C++ Developer Reference
- Migrating the MonteCarloMultiGPU from CUDA* to SYCL* (Source Code)
- Guided cuBLAS Examples for SYCL Migration
- Migrate from CUDA* to C++ with SYCL*
- Intel® DPC++ Compatibility Tool
- SYCLomatic Overview
- Codeplay* oneAPI for NVIDIA GPUs
Get the Software
oneMKL is available standalone or as part of the Intel® oneAPI Base Toolkit. In addition to these download locations, they are also available through partner repositories. Detailed documentation is also available online.