
Background
Challenges associated with data privacy, limited data availability, data labeling, ineffective data governance, high cost, and the need for a high volume of data are driving the use of synthetic data to fulfill the high demand for AI solutions across industries.
There is a growing interest in medical diagnosis systems using deep learning. However, due to proprietary and privacy reasons, the data access to the public has been very limited and thereby leading to limited public contributions in this field of study. As well, access to medical image data without expert annotations and accurate metadata renders the data useless for most modern applications. This has led to a larger interest in generating synthetic data since it can be used for deep learning model training and validation while vastly reducing the costs of data collection and labeling.
Solution
In collaboration with Accenture*, Intel developed a synthetic image generation AI reference kit that may help you with generating images that can be used for deep learning.
This example of synthetic image generation targets a use case in the medical industry by using synthetic data generation of retinal images for vessel extraction. A detailed interpretation and study of the retinal vasculature relies on precise vessel segmentation, which is a laborious and time-consuming task. Additionally, public data sources of retinal images are limited and are bound by strict privacy clauses. A synthetic data generation of the images helps to provide a larger data source to aid with developing a model from the existing and limited data sources.
End-to-End Flow Using Intel® AI Software Products
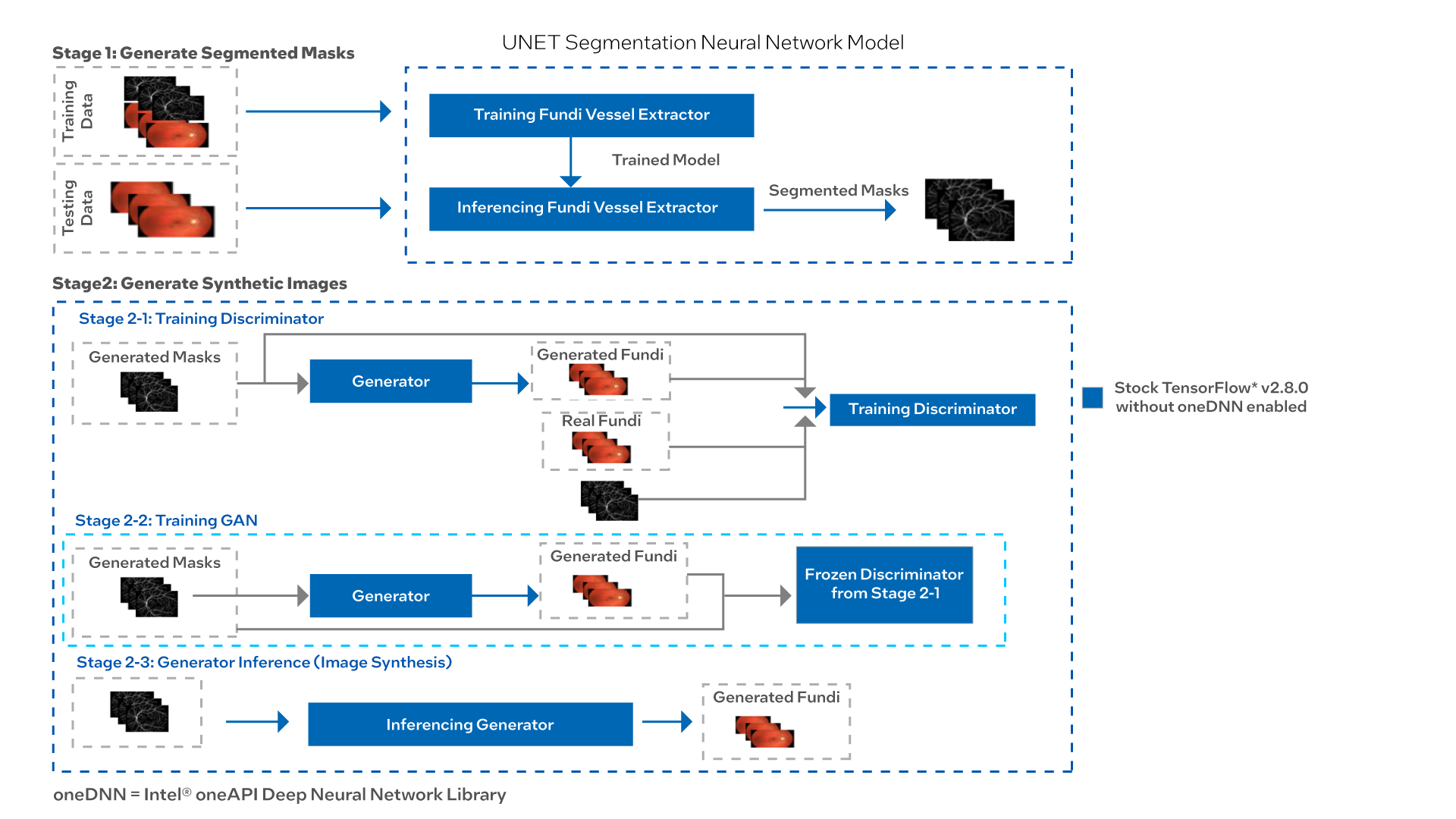
An AI-enabled image generator aid helps to generate new accurate image and image segmentation datasets when the dataset is limited.
A two-stage pipeline is considered for generating synthetic medical images of retinal fundi using generative adversarial networks:
Stage 1: Generate segmented images from a U-Net model using a real dataset of fundi images.
Stage 2: Generate synthetic retinal fundi image from a GAN model using a real dataset of fundi images and segmented pairs generated in Stage 1.
By quantizing and compressing the model (from floating point to integer model) while maintaining a similar level of accuracy as the floating-point model, efficient use of underlying resources is demonstrated when deployed on edge devices with lower processing and memory capabilities.
This reference kit includes:
- Training data
- An open source, trained model
- Libraries
- User guides
- Intel® AI software products
At a Glance
- Industry: Health and life sciences (HLS), Cross-industry
- Task: Data preprocessing, image segmentation, image generation
- Dataset: 15 images of healthy patients, 15 images of patients with diabetic retinopathy, and 15 images of glaucomatous patients. Binary gold standard vessel segmentation images are available for each image and masks determining field of view (FOV).
- Type of Learning: Deep learning
- Models: U-Net CNN, GAN CNN
- Output: Synthetic image data
- Intel AI Software Products:
- Intel® Optimization for TensorFlow* v2.11.0
- Intel® Neural Compressor
Technology
Optimized with Intel AI Software Products for Better Performance
The image data generation model was optimized by Intel Optimization for TensorFlow. Intel Neural Compressor is used to quantize the FP32 Model to the int8 model.
Intel® Extension for PyTorch* and Intel Neural Compressor allow you to reuse your model development code with minimal code changes for training and inferencing.
Performance benchmark tests were run on Microsoft Azure* Standard_D8_v5 using 3rd generation Intel® Xeon® processors to optimize the solution.
Benefits
Synthetic image generation helps to provide a larger data source to aid the model development for those areas where limited data sources exist, such as the medical field.
This reference kit implementation provides a performance-optimized guide around synthetic image-generation use cases that can be scaled across similar use cases in various domains.
Machine learning developers need to train models for a substantial number of datasets. The ability to accelerate training allows them to train more frequently and achieve better accuracy. Faster inferencing speed may enable them to run prediction in real time as well as offline batch processing.
With Intel® oneAPI components, little to no code change is required to attain the performance boost.
