Introduction
Memory management is a core aspect of the Data Plane Development Kit (DPDK). It provides a solid foundation upon which both other parts of DPDK and user applications are built to perform their best. In this series of articles, we take a close look at the various memory management features provided by DPDK.
However, before we get into detail on the various memory-related features provided by DPDK, it is important to provide some perspective on why memory management in DPDK works the way it does, and what the principles are that lie behind it. This article covers these principles and explains how they help in achieving DPDK’s high performance.
Note While DPDK supports FreeBSD*, and there is also a work-in-progress Windows* port, the majority of memory-related features are currently only available on Linux*.
Huge Pages
In modern CPU architectures, memory is not managed as individual bytes, but rather using pages—virtually and physically contiguous blocks of memory. These blocks of memory are usually (but not necessarily) stored in RAM. On Intel® 64 and IA-32 architectures, standard system page size is 4 kilobytes.
When code is run, page addresses for accessing memory locations need to be translated from virtual addresses used by software applications to physical addresses used by the hardware. This translation is done by way of page tables, which map virtual to physical addresses, on a page level of granularity. To improve performance, the most recently used page addresses for accessed memory locations are kept in a cache called the translation lookaside buffer (TLB). Each page occupies an entry in the TLB. If your code accesses (or has recently accessed) 16 kilobytes of memory—that is, four pages—then there is a good chance that these pages will be in the TLB cache.
If one of those pages is not in the TLB cache, any attempt to access addresses contained within that page will cause a TLB miss; that is, the operating system (OS) will have to fetch the page address from its global page table into the TLB. TLB misses are therefore relatively expensive (and can get really expensive in some cases), so it is preferable to have as few TLB misses as possible by having all currently active pages in the TLB.
However, the TLB is not infinite in size; it is actually quite small, and the amount of memory covered by the TLB for standard page sizes at any given moment is pretty insignificant (a few megabytes) compared to the amount of data DPDK usually deals with (sometimes up to tens of gigabytes). This means that, were DPDK to use regular memory, applications using DPDK would experience a significant performance degradation due to the high rate of TLB misses.
To address this problem, DPDK relies on huge pages. It is easy to guess from their name that huge pages are like regular pages, only bigger. How much bigger? On Intel 64 and IA-32 architectures, the two currently available HugePage sizes are 2 megabyte (MB) and 1 gigabyte (GB). That means a single page can cover an entire 2 MB or 1 GB physically and virtually contiguous memory area.
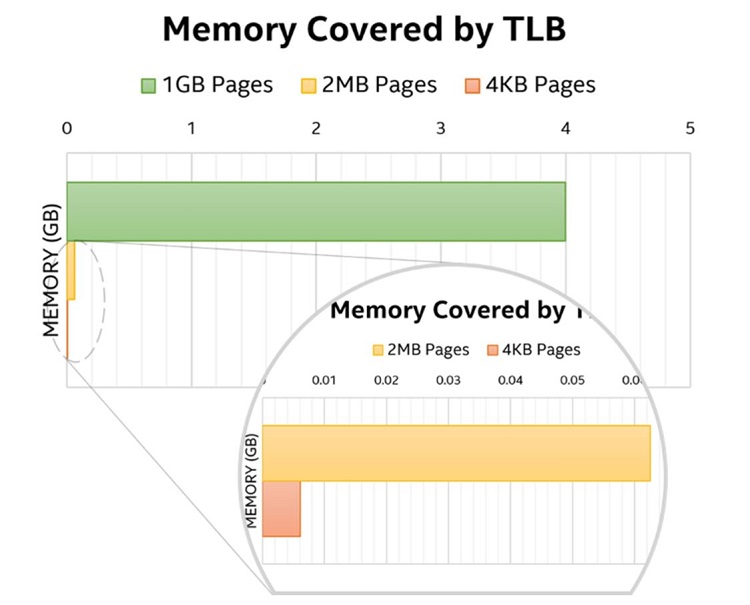
Figure 1. TLB memory coverage comparison.
DPDK supports both of these page sizes. With those page sizes, it is much easier to cover large memory areas without (as many) TLB misses. Fewer TLB misses, in turn, leads to better performance when working with large memory areas, as is customary for DPDK use cases.
Pinning Memory to NUMA Nodes
When regular memory is allocated, it can, in theory, be physically located anywhere in RAM. This is not an issue on a single-CPU system, but many DPDK consumers run their applications on multi-CPU systems with non-uniform memory access (NUMA) support. With NUMA, all memory is not equal: some memory accesses will take longer than others due to their physical location in relation to the CPU doing said memory accesses. When using regular memory allocation there often is no control over where this memory gets allocated, so if DPDK uses regular memory on such a system, it is possible to end up in a situation where a thread executing on one CPU unintentionally accesses memory belonging to a non-local NUMA node.
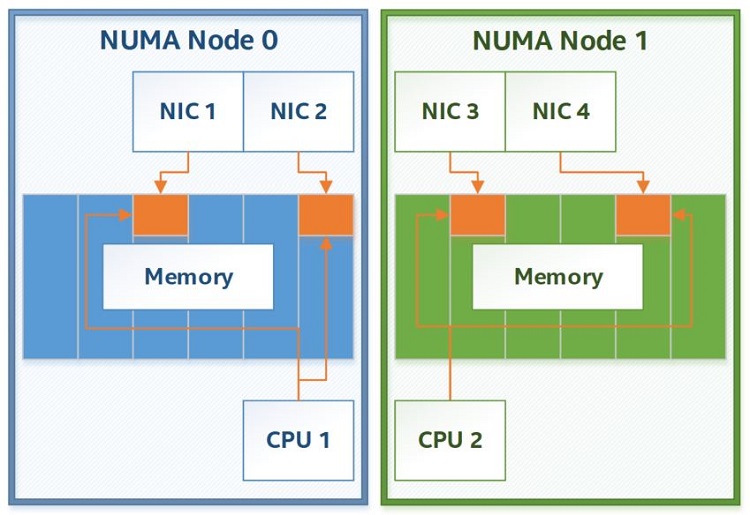
Figure 2. Ideal NUMA node allocation.
Admittedly, such cross-NUMA node accesses would be rare on any modern OS as they are all NUMA-aware, and there are ways to enforce NUMA locality for memory without DPDK. However, what DPDK brings to the table is not just NUMA-awareness; rather, it is the fact that the entirety of DPDK’s API is structured around explicit NUMA awareness for every operation. There is often no way to allocate a given DPDK data structure without explicitly requesting NUMA node access where said structure will have to be located in memory.
Such explicit NUMA awareness throughout the DPDK API helps to ensure that NUMA awareness is always a consideration in every operation performed by a user application; in other words, the DPDK API makes it harder to write poorly performing code.
Hardware, Physical Addresses, and DMA
DPDK was conceived as a set of user space packet I/O libraries, and to this day it largely stays true to its original mission statement. However, hardware does not work with user space virtual addresses—it is unaware of any user space processes, and thus lacks the context required to understand where user space virtual addresses point to. Instead, it works using real physical addresses; that is, the addresses that the CPU, RAM, and all other parts of the system use to communicate to each other.
Modern hardware almost always uses direct memory access (DMA) transactions for efficiency reasons. Normally, in order to perform a DMA transaction, the kernel would need to be involved to create a DMA-enabled memory area, translate the in-process virtual address to a real physical address that can be understood by the hardware, and to initiate the DMA transaction. This is how I/O works in most modern operating systems; however, this is a time-consuming process that requires context switching and translation and lookup operations that are not conducive to high-performance I/O.
DPDK’s memory management addresses this problem in a simple way. Whenever a memory area is made available for DPDK to use, DPDK figures out its physical address by asking the kernel at that time. Since DPDK uses pinned memory, generally in the form of huge pages, the physical address of the underlying memory area is not expected to change, so the hardware can rely on those physical addresses to be valid at all times, even if the memory itself is not used for some time. DPDK then uses these physical addresses when preparing I/O transactions to be done by the hardware, and configures the hardware in such a way that the hardware is allowed to initiate DMA transactions itself. This allows DPDK to avoid needless overhead and to perform I/O entirely from user space.
IOMMU and IOVA
By default, any hardware has access to the entire system, so it can perform DMA transactions anywhere. This has a number of security implications. For example, a rogue and/or untrusted process (including one running inside a virtual machine (VM)) could potentially use a hardware device to read from and write to kernel space, and just about any other memory location. To address this problem, modern systems come equipped with an input-output memory management unit (IOMMU). This is a hardware device that provides DMA address translation and device isolation facilities, so that a particular device is only allowed to perform DMA transactions to and from certain memory areas (designated by the IOMMU), and cannot access the rest of the system memory address space.
Due to the involvement of IOMMU, the physical address the hardware uses may not be the real physical address, but instead a (completely arbitrary) input-output virtual address (IOVA) assigned to the hardware by the IOMMU. Generally, the DPDK community uses the terms physical address and IOVA interchangeably, but, depending on context, the difference between the two might matter. For example, DPDK 17.11 and the newer long-term support (LTS) versions of DPDK may not use actual physical addresses at all in certain circumstances, and may instead use user space virtual addresses (or even completely arbitrary addresses) for DMA purposes. The IOMMU takes care of address translation, so the hardware never notices the difference between the two.
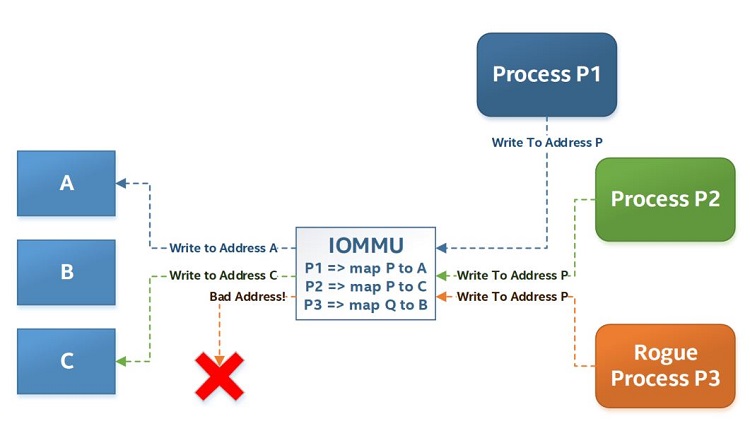
Figure 3. Example of IOMMU remapping physical to IOVA addresses.
Depending on how DPDK was initialized, IOVA addresses may or may not represent actual physical addresses, but one thing is always true: DPDK is aware of the underlying memory layout, and can therefore take advantage of that. For example, it can map pages in such a way as to create IOVA-contiguous virtual areas, or even make use of IOMMU to rearrange the memory maps to make memory appear IOVA-contiguous, even though the underlying physical memory may not be.
As a result, this awareness of underlying physical memory areas is one more tool in DPDK’s tool belt. Most data structures do not care about IOVA addresses, but when they do, DPDK provides the facilities for software and hardware to take advantage of physical memory layout, and optimize for different use cases.
Note the IOMMU will not set up any mappings by itself. Rather, the platform, the hardware, and the OS must be configured to use IOMMU. Such configuration instructions are out of scope for this series of articles, but there are instructions available in the DPDK documentation and elsewhere. Once the system and the hardware are set up to use IOMMU, DPDK is able to use IOMMU to set up DMA mappings for any memory areas allocated by DPDK. Making use of IOMMU is the recommended way to run DPDK, as doing so is more secure, and it provides usability advantages.
Memory Allocation and Management
DPDK does not use regular memory allocation functions such as malloc(). Instead, DPDK manages its own memory. More specifically, DPDK allocates huge pages and creates a heap out of this memory, to give out to user applications and to use for internal data structures.
Using a custom memory allocator has a number of advantages. The most obvious one is the performance benefit for the end applications: DPDK creates memory areas to be used by the application, and the application can take advantage of huge page support, NUMA node affinity, access to DMA addresses, IOVA contiguousness, and so on, without any additional effort.
DPDK memory allocations are always aligned on CPU cache line boundaries—the start address of each allocation will be a multiple of the cache line size for the system. Such an approach prevents many common performance problems such as unaligned accesses and false sharing of data, where a single cache line inadvertently contains (possibly unrelated) data being accessed by multiple cores at once. Alignment by any other power-of-two value (>= cache line size, of course) is also supported for use cases that require such alignment (for example, allocating hardware ring structures).
Any memory allocation in DPDK is also thread-safe. This means that any allocation taking place on any core will be atomic, and will not interfere with any other allocations. This may seem like a triviality (after all, regular glibc memory allocation routines are generally thread-safe as well), but its significance becomes clearer once it is considered in the context of multiprocessing.
DPDK supports a specific flavor of cooperative multiprocessing, where a primary process manages all DPDK resources, and multiple secondary processes can attach to the primary process and have shared access to resources managed by the primary process.
DPDK’s shared memory implementation works by not only mapping the same resources in different processes (similar to mechanisms like shmget()), but by also duplicating the primary process’s address space inside another process. Therefore, since everything is located at the same addresses within both processes, any pointers to DPDK memory objects will work across processes, without any address translation necessary. This is very important for performance when passing data across processes.
Table 1. Comparison between OS and DPDK allocators.
| Regular Linux* allocator 1 | DPDK rte_malloc | |
|---|---|---|
| Huge page memory support | Not enforced | Default |
| NUMA node pinning | Not enforced | Default |
| Access to IOVA addresses | No | Yes |
| IOVA-contiguous memory | No | Yes |
| Cache-aligned allocations | Not enforced | Enforced |
| Arbitrary alignment for allocations | Yes | Yes |
| Full shared memory for multiprocessing | No | Yes |
| Multiprocess thread safety | No | Yes |
1. There are third-party libraries that can provide each of these features, but there is not one library that provides all of them.
The shared nature of DPDK’s memory is also why thread safety of the DPDK heap is hugely important; not only can any thread allocate and deallocate data concurrently with any other thread, but any process can allocate and deallocate memory concurrently with multiple other processes, without any race conditions. Because the entire DPDK memory heap is shared across processes, it is also perfectly safe to allocate memory in one process and reference or free it in another.
Memory Pools
DPDK also has a memory pool manager that is widely used throughout DPDK to manage large pools of objects of fixed size. Its uses are many—packet I/O, crypto operations, event scheduling, and many other use cases that need to quickly allocate or deallocate fixed-sized buffers. DPDK memory pools are highly optimized for performance, and support optional thread safety (users do not pay for thread safety if they don’t need it) and bulk operations, all of which result in allocation or free operation cycle counts per buffer reaching low double-digit values.
That said, even though the subject of DPDK memory pools pops up in just about every discussion on memory management in DPDK, the memory pool manager is technically a library built on top of the regular DPDK memory allocator. It is not part of standard DPDK memory allocation facilities, and its internal workings are completely separate from (and very different than) the DPDK memory management routines. For this reason, it is out of scope for this article series. However, more information about the DPDK memory pool manager library can be found in the DPDK documentation.
Conclusion
This article covered many of the core principles that lie at the foundation of DPDK’s memory management subsystem, and demonstrated that high performance of DPDK is not an accident, but rather a deliberate consequence of its architecture.
The following articles in this series present a deep dive into IOVA addressing and its use in DPDK, provide a historical perspective on memory management features available in DPDK long term support (LTS) releases 17.11 and earlier, and describe the changes and new features available in 18.11 and later DPDK versions.
Helpful Links
DPDK documentation for current release
DPDK documentation for previous releases
About the Author
Anatoly Burakov is a software engineer at Intel. He is the current maintainer of VFIO and memory subsystems in DPDK.