Introduction
Discontinuity in big data infrastructure drives storage disaggregation, especially in companies experiencing dramatic data growth after pivoting to AI and analytics. This data growth challenge makes disaggregating storage from compute attractive because the company can scale their storage capacity to match their data growth, independent of compute. This decoupled mode allows the separation of compute and storage, enabling users to rightsize hardware for each layer. Users can buy high-end CPU and memory configurations for the compute nodes, and storage nodes can be optimized for capacity.
Many traditional companies who were formerly big users of Oracle* Real Application Clusters (RAC) or Oracle Exadata* are now looking for solutions to move off these platforms to something more cloud-like, open source, and that can be readily integrated into their AI analytics investments. By decoupling compute and storage, multiple compute clusters running Apache Hadoop*, Apache Spark*, Apache Kafka*, MongoDB*, Apache Cassandra*, or data science tools like TensorFlow* can share access to a common data repository or data lake. This leads to cost savings in storage capacity. Enterprise-grade shared storage with consistent performance and a rich set of data services can be used for simplified data management and reduced provisioning overheads. This can also help simplify and improve security by using shared storage data-at-rest encryption capabilities.
According to IDC, through 2020, spending on cloud-based big data analytics technology will grow 4.5 times faster than spending for on-premises solutions1. Similarly, Gartner has noted, "Cloud-based big data services offer impressive capabilities like rapid provisioning, massive scalability, and simplified management." And in the report "Move Your Big Data into The Public Cloud" 2 sponsored by Oracle and Intel, Forrester Research wrote, "companies that move more into the cloud for big data analytics achieve greater innovation, increased integration, and higher levels of security," and “Public cloud adoption is the top priority for technology decision makers investing in big data.”
When running big data in cloud-based storage, new technologies like Storage Performance Developer Kit (SPDK), remote direct memory access (RDMA), and Intel® Optane™ DC persistent memory can be used to accelerate performance. Today, a long I/O stack of big data buries hardware performance, but it is challenging to shorten the stack to eliminate unnecessary kernel and user space copy.
This whitepaper is a continuation of Unlock Big Data Analytics Efficiency with Compute and Storage Disaggregation on Intel® Platforms3.
Cloud Architecture Evolution for Big Data Analytics
Storage Disaggregation
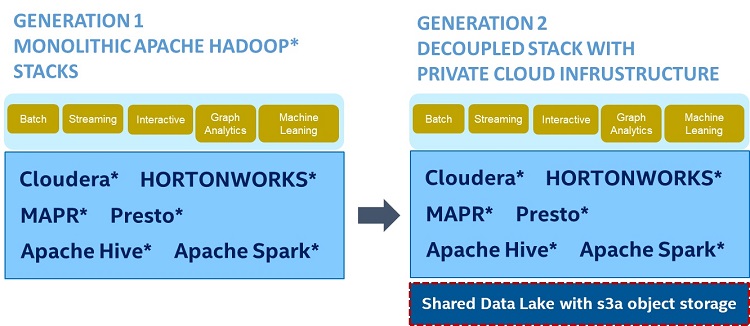

Figure 1. Storage disaggregation
Disaggregating storage from big data compute services is becoming increasingly popular in data centers. Running Spark*4 on disaggregated cloud storage introduces benefits such as liberating clusters from performance and scalability limitations, simplifying data center management with a shared data lake, and reducing total cost of ownership (TCO).
To evaluate performance differences between running big data on traditional on-premise configuration and on disaggregated cloud storage, we scheduled three types of workloads, covering batch queries, IO intensive workloads, and CPU intensive workloads.
This evaluation uncovered two significant performance gaps: first, cloud storage does not natively act like a file system and lacks critical features such as transactional rename support, and second, cloud storage takes less advantage of system memory as buffers or page caches. We identified optimizations that can be made to overcome these performance gaps. We describe the analysis and two optimizations in the next section.
Disaggregate Storage with In-Memory Acceleration

Figure 2 In-memory acceleration
After evaluating running big data on both disaggregated cloud storage and a provisioned orchestration framework, we noticed that to make solutions for big data increasingly more scalable and flexible, there is an urgent need to optimize disaggregated cloud storage performance.
The solution is to add an in-memory acceleration layer to eliminate the two main issues that cause performance degradation. The first issue is that disaggregated cloud storage lacks filesystem semantics like rename; the other issues is that disaggregated cloud storage can’t leverage memory for use as buffers and page caches. Adding an In-memory acceleration layer solves both issues, so we can both maximize the benefit realized by cloud storage and achieve competitive or even better performance than traditional on-premise configuration.
Storage Disaggregation
Configurations
System Configuration
The test cluster consists of ten nodes, including five compute nodes and five storage nodes. All of the nodes are equipped with Intel® Xeon® processor E5-2699 version 4.
For the compute nodes, we ran five Spark executors for each node, using 5* 22 G memory with two Intel® Solid State Drive Data Center or Intel® SSD Data Center (Intel® SSD DC) as Spark shuffle devices.
For the storage node, we ran both the Hadoop Distributed File System (HDFS*)5 and Ceph*6 on seven 1TB HDDs on each node. The total storage pool size is 5 * 7 / 3(replica) = 11.6T. For Ceph, we deployed Ceph* radosgw on each node to fully use network bandwidth. In comparison with HDFS*, Ceph* OSD requires Ceph* radosgw to communicate with Spark* executors as the I/O path will be longer than by using HDFS*. When using S3A Ceph* as a backend, the read I/O path should be from Ceph* OSD to Ceph* Radosgw to Spark*, which is much longer than when using HDFS*, where the read I/O path is from the HDFS* Datanode directly to Spark* executors.
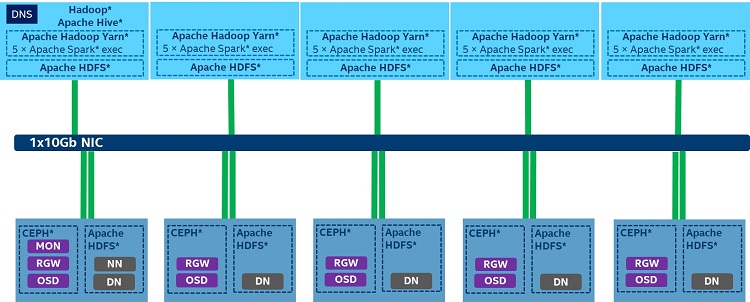
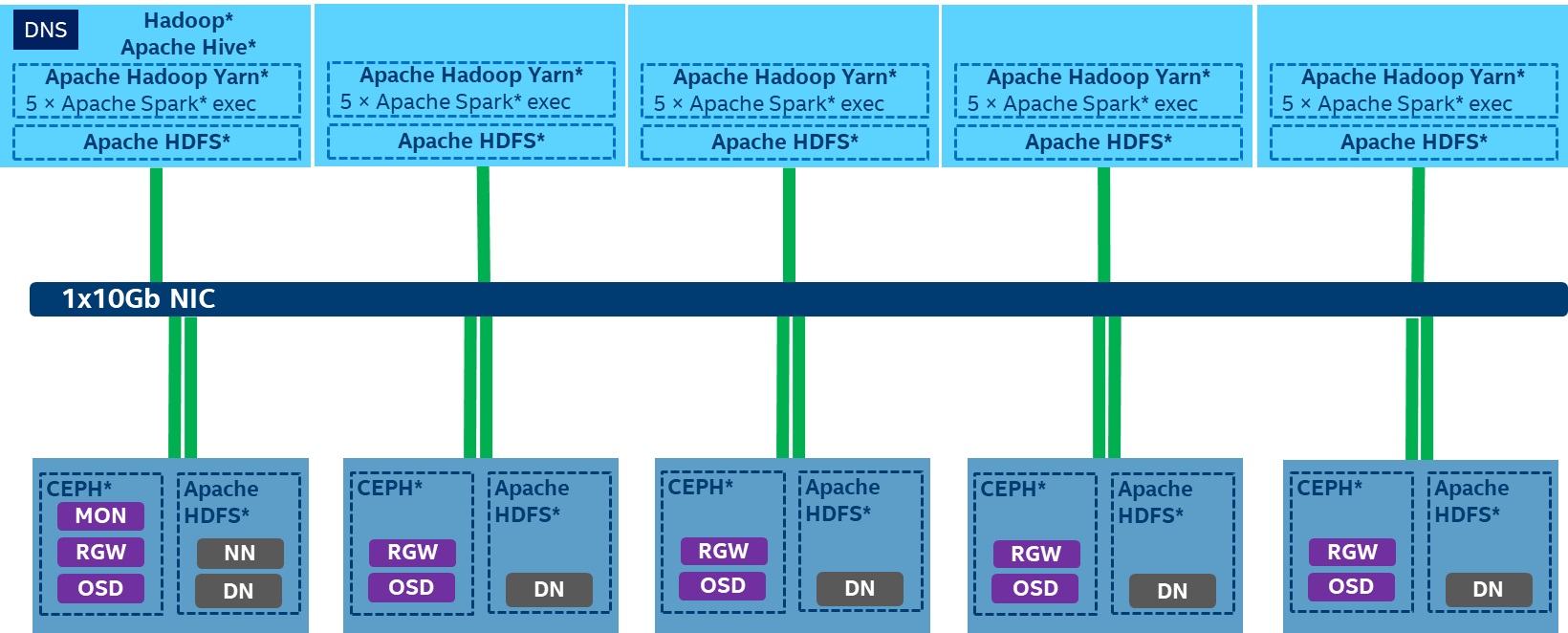
Figure 3. Storage disaggregation configuration
Table1. Compute nodes configuration
| Compute Node Configuration | |
|---|---|
| CPU | Intel® Xeon™ processor Gold 6140 @ 2.3 GHz |
| Memory | 384 GB |
| NIC | Intel Corporation Ethernet Connection X722 for 10GBASE-T |
| Storage | 5 Intel® SSD DC P4500 Series (two for Spark* shuffle) |
| Software Configuration | Hadoop* 2.8.1; Apache Spark* 2.2.0; Apache Hive* 2.2.1; CentOS 7.5, JDK 1.8.0_131 |
Table2.Storage nodes configuration
|
Storage Node Configuration |
|
|---|---|
| CPU | Intel® Xeon™ processor Gold 6140 @ 2.3GHz |
| Memory | 192 GB |
| NIC | 2 Intel Corporation Ethernet Connection X722 for 10GBASE-T |
| Storage | 7 1TB HDD for Red Hat Ceph BlueStore* or Apache Hadoop Distributed File System* (HDFS) NameCode and DataNode |
| Software Configuration | Hadoop* 2.8.1; CentOS 7.5; Ceph Luminous (12.2.5) |
Test Methodology
To simulate common usage scenarios in big data applications, we tested three use cases:
- Batch Query Analytics
We leveraged 54 queries derived from TPC-DS*7 (TPC benchmark with decision support) with intensive reads across objects in different buckets to consistently execute analytical processes of a large set of data. For data preparation, we built a 1 T text dataset and transformed it into Parquet format, and then dropped the page cache before each run to eliminate performance impact. - I/O Intensive Benchmark
We used Terasort as our I/O intensive benchmark. Terasort is a popular benchmark that measures the amount of time to sort one terabyte of randomly distributed data on a given computer system. Since Terasort needs to read the entire 1T of data from storage, then sort it and write it back to storage, bandwidth strongly impacts its performance. - CPU Intensive Benchmark
We used K-means as our CPU intensive workload. The K-Means algorithm iteratively attempts to determine clusters within the test data by minimizing the distance between the mean value of cluster center vectors, and the new candidate cluster member vectors. This requires a large number of distance calculations in each iteration of the data set. So, for K-means, once data is promoted from storage, it is a CPU-intensive workload to Spark. In our test, the dataset size is 360 GB.
Disaggregated Cloud Storage
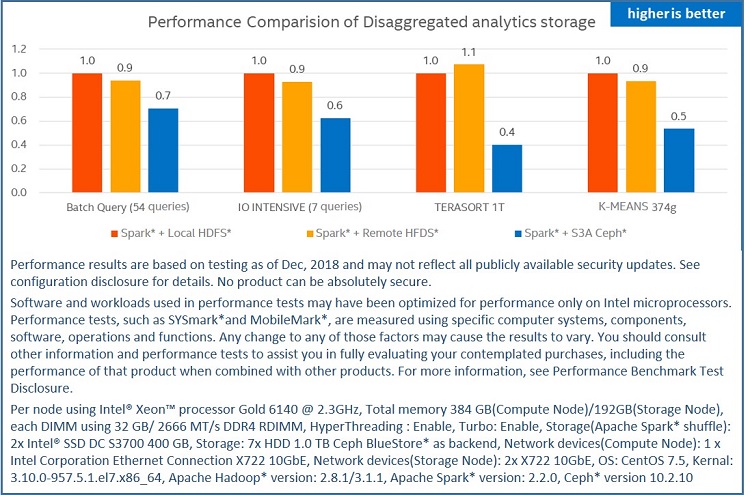

Figure 4. Performance evaluation with storage disaggregation
To better evaluate and analyze the performance of storage disaggregation, we conducted tests using three different configurations: traditional on-premise configuration with co-located HDFS* and compute, disaggregated HDFS* to storage side, and disaggregated cloud storage by Ceph*. These tests show how network and storage implementation impact performance.
For the disaggregated HDFS* vs. co-located HDFS* configuration test, the performance impact is quite slight. For batch queries, disaggregated HDFS* showed a 10% performance degradation. I/O intensive workloads, using Terasort with a 1T dataset, disaggregated HDFS* showed better performance than co-located HDFS since there were ten nodes tested on disaggregated HDFS* but only five nodes in the co-located HDFS*. So, the total memory size of disaggregated HDFS* is 1.5x bigger than the co-located HDFS*. For the CPU intensive test, we barely saw a difference with these two configurations.
There are performance gaps when comparing disaggregated S3A Ceph* cloud storage vs. co-located HDFS* configurations. For batch queries, disaggregated S3A Ceph* cloud storage showed a 30% performance degradation. The I/O intensive workload using Terasort had a performance degradation as significant as 60%. And for CPU intensive workload using K-means, the performance also showed 50% degradation.
After further investigating system data, we noticed that there are two main reasons leading to the negative performance impact seen with disaggregated S3A Ceph cloud storage. One major cause is that when using S3A Ceph cloud storage in the Hadoop* system, we relied on an S3A adapter. S3A is not a filesystem and does not natively support transactional writes (TW). Most big data analytics software (such as Apache Spark or Apache Hive) rely on the HDFS’s atomic rename feature to support atomic writes and during job submit, tasks submit output to temporary locations first, only moving (renaming) data to the final location upon job completion. Since S3A lacks native support for moving and renaming, it implements this with: copy + delete + head + post, a combination of operations which adds additional read and write bandwidth to cloud storage. Figure 5 demonstrates this behavior. S3A Ceph cloud storage network bandwidth is shown on the left side, and disaggregated HDFS network bandwidth is shown on the right side. The read bandwidth line shown on the left side is caused by S3A using read and write to implement moving.
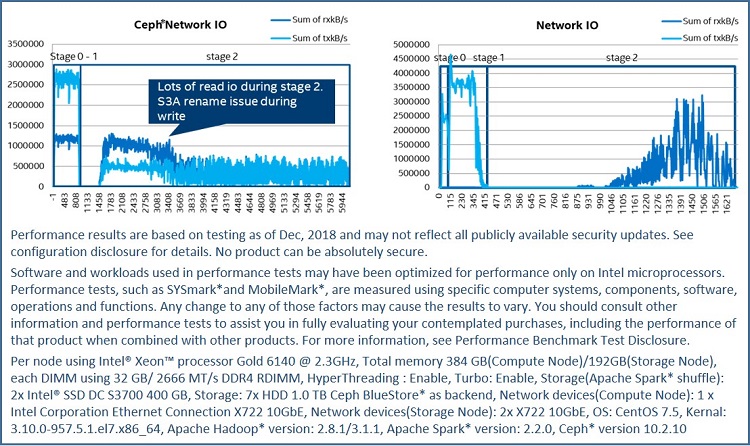

Figure 5. Network I/O comparison between S3A Ceph and HDFS
Another cause is that disaggregated S3A Ceph cloud storage can’t use memory as buffers and page cache as HDFS did since cloud storage lacks a good data-locality concept compared to HDFS, and has a different implementation for data consistency. I/O in cloud storage will Ack until all replications hit disks while in HDFS case, I/O may Ack a completion when replications hit data node buffers. As shown in Figure 6, on Ceph, memory utilization is about 25% while the memory is almost used up in HDFS case.
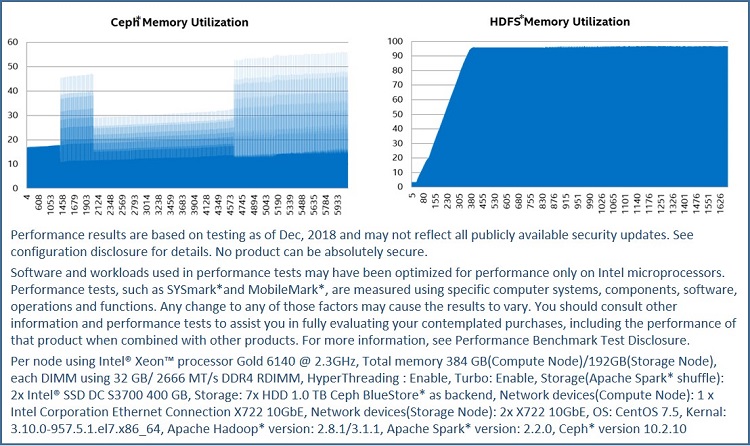

Figure 6. Storage side memory comparison between S3A Ceph and HDFS
S3A Connector Adapter Optimization
Since the implementation of an S3A job commit mechanism greatly impacts cloud storage performance, a new feature called S3A Committer8 has been part of Hadoop since version 3.1.1. S3A Committer makes explicit use of this multipart upload (“MPU”) mechanism and provides two optimized protocols to make data output much faster. In Table 3, we list these two committers, staging and magic, with their operations in different phases.
Table 3. S3A committer implementation
| Feature | Staging | Magic |
|---|---|---|
| Task Output Destination | local disk | S3A without completing the write |
| Task Commit Process | upload data from disk to S3 | list all pending uploads on s3 and write details to job attempt directory |
| Task Abort Process | delete local disk data | list all pending uploads and abort them |
| Job Commit | list and complete pending uploads | list and complete pending uploads |
In our test of the staging committer, temporary output data is written to local disk first when tasks commit, with the result that data will be written to cloud storage only once.
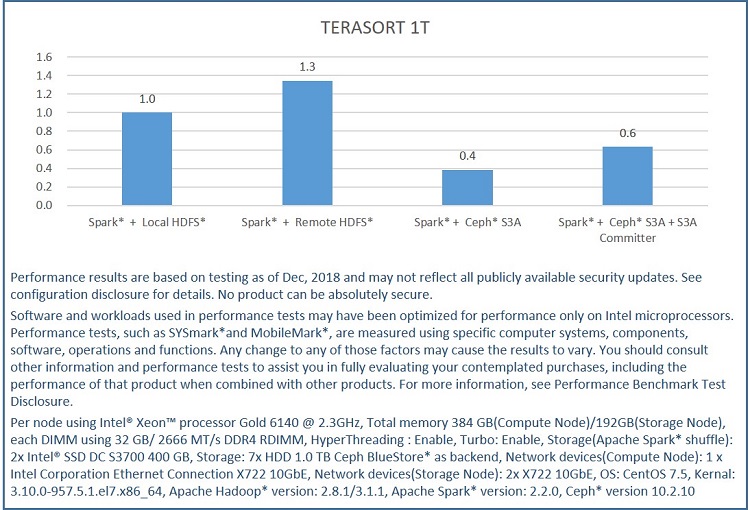

Figure 7. Performance comparison with S3A committer
Performance improved by 1.5 times after using an S3A committer (staging committer), and in Figure 8, you can see the read I/O in the output stage is gone.
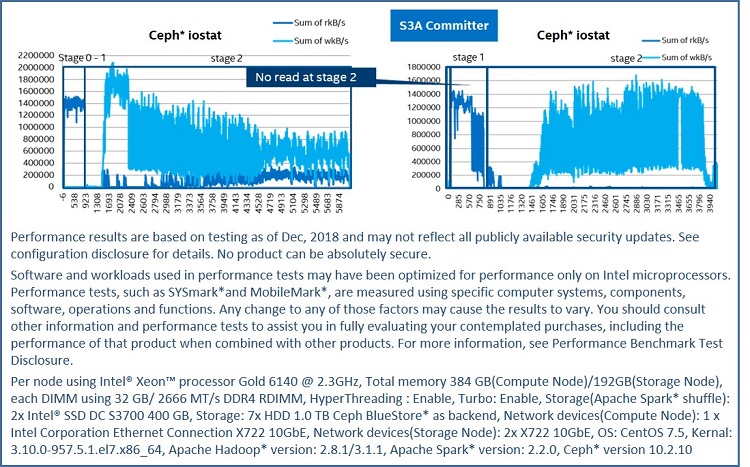

Figure 8. I/O state comparison with and without an S3A committer
There is still 40% performance degradation with S3A Committer compared with that of co-located HDFS.
In-Memory Data Acceleration
Cloud Big Data Analytics with In-Memory Data Acceleration
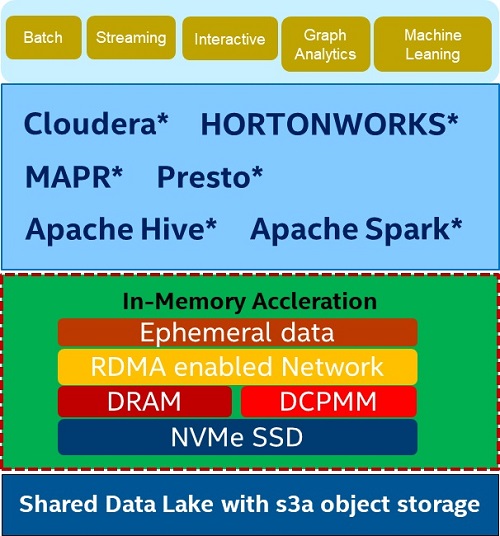
Figure 9. Cloud big data analytics with in-memory data acceleration
In the above chapters, we evaluated storage disaggregation and S3A adapter optimization and noticed two issues causing performance gaps between disaggregated cloud storage and a traditional on-premise configuration. To further optimize Spark on disaggregated cloud storage and to benefit from rapid provisioning, excellent scalability, easy management, and pay as you grow flexibility, we added an “In-Memory Data Acceleration” layer to support big data filesystem operation natively and better utilize memory to improve the performance.
Accelerating with In-Memory Data Acceleration as Cache
Configurations
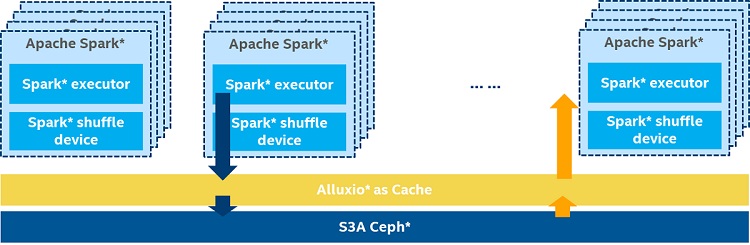
Figure 10. Accelerating with Alluxio* as cache
To eliminate the existence overhead of S3A, we proposed adding a memory layer between the storage systems and the computation frameworks and applications to accelerate Spark* process speed. As shown in Figure 10, when using Alluxio*9 as a cache layer, data is promoted from Ceph* to a Spark* executor local Alluxio* worker and then used by Spark. And when a Spark executor outputs data back to Ceph, it outputs data to Alluxio first then flushes to Ceph asynchronously.
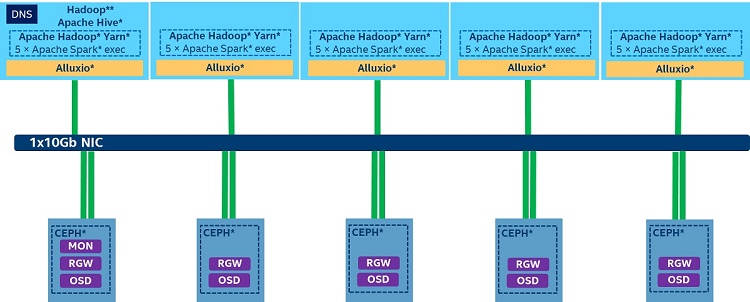

Figure 11. Alluxio* as cache system configuration
Table 4. Compute nodes configuration
|
Compute Nodes Configuration |
|
| Software Configuration | Hadoop* 2.8.1; Apache Spark* 2.2.0; Apache Hive* 2.2.1; CentOS 7.5; Alluxio* 2.0.0 |
In this test, we evaluated the performance of using Alluxio as cache on S3A Ceph cloud storage, since we still saw a 40% performance degradation when running Terasort on there compared with a traditional on-premise configuration with S3A connector optimization.
We used Alluxio 2.0.0 in this test, deploying Alluxio workers to all Spark running nodes, with the assumption that since we are using Spark in Yarn, and Spark executors may switch to different physical nodes every time, the benefit we may observe from Alluxio is better promoting and flushing I/O behavior.
Performance and Analysis
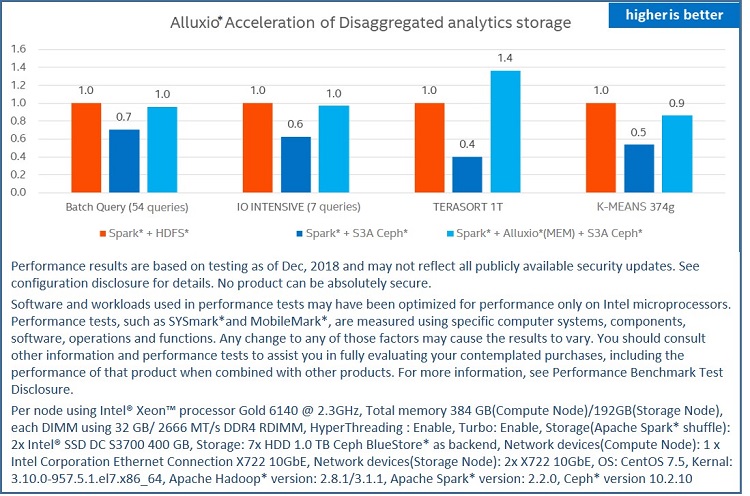

Figure 12. Performance evaluation with Alluxio* as In-Memory acceleration
We tested deploying Alluxio with five 200 GB Memory. All Alluxio tests are based on the disaggregated S3A Ceph cloud storage configuration, enabling us to see the exact performance improvement after adding the in-memory data acceleration.
The results showed that ;both configurations provide a significant performance improvement.
For batch queries, performance with Alluxio shows more than 1.42 times improvement compared with disaggregated S3A Ceph cloud storage and similar performance to a traditional on-premise configuration. For the I/O intensive workload on Terasort, performance with Alluxio shows more than a 3.5 times improvement. And when compared with traditional on-premise configuration, disaggregated S3A Ceph cloud storage with Alluxio shows a 1.4 times performance improvement in the Terasort test. For CPU intensive workload using K-Means, performance with Alluxio shows 1.4 times improvement while compared to traditional on-premise configuration and performance with Alluxio disaggregate S3A Ceph cloud storage still indicates 10% worse than traditional on-premise configuration.
So, from the above data, we can conclude that using Alluxio as the cache can eliminate the performance overhead of S3A and there is still a benefit when deploying big data on cloud storage. When the workload is I/O intensive, it is even more beneficial to adopt Alluxio as the cache.
Further work
In-Memory Data Acceleration with Spark-PMoF
Design and Objective
We have shown that using an in-memory data accelerator (IMDA) as Spark cache improved the Spark process speed significantly, and for further optimization, we propose a Spark module called Spark-PMoF, which will enable Intel® Optane™ DC persistent memory module and RDMA support in Spark shuffle and also external Spark shuffle.
The workflow for use of Spark-PMoF as an IMDA layer is shown in Figure 13. Shuffle data will be written to Intel Optane DC persistent memory using the Persistent Memory Development Kit (PMDK), and shuffle data transmission among executors leverages RDMA to bypass some memory copy and offload CPU cycles.
Initial implementation and evaluation are complete and will be covered in the next paper in this series.
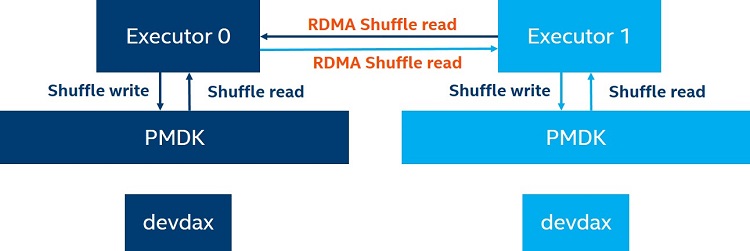
Figure 13. In-memory data acceleration (IMDA) with Spark-PMoF
Summary
In this paper, we evaluated performance using three configurations: storage disaggregation, accelerating disaggregated cloud storage with S3A committer, and accelerating disaggregated cloud storage with in-memory data acceleration as the cache. According to our evaluation, performance with disaggregate cloud storage shows gaps between 10% - 40% in comparison with traditional on-premise configuration.
Deployment of IMDA as cache, tested by an IO intensive workload, showed 3.5 times the improvement seen with disaggregated storage, and 1.4 times the improvement compared to a traditional on-premise configuration.
Reference
- IDC FutureScape: Worldwide Big Data and Analytics 2016 Predictions
- Move Your Big Data Into The Public Cloud
- Unlock Big Data Analytics Efficiency with Compute and Storage Disaggregation on Intel® Platforms
- Apache Spark
- Apache Hadoop
- Ceph
- TPCDS
- S3A Committer S3A committer
- Alluxio
Notices
Software and workloads used in performance tests may have been optimized for performance only on Intel® microprocessors. Performance tests, such as SYSmark* and MobileMark*, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.
§ Configurations: [describe config + what test used + who did testing].
§ For more information go to http://www.intel.com/performance.