Visible to Intel only — GUID: GUID-7C6574A1-164E-4A4A-A0F9-75949A5B35F7
Getting Help and Support
What's New
Notational Conventions
Overview
OpenMP* Offload
BLAS and Sparse BLAS Routines
LAPACK Routines
ScaLAPACK Routines
Sparse Solver Routines
Extended Eigensolver Routines
Vector Mathematical Functions
Statistical Functions
Fourier Transform Functions
PBLAS Routines
Partial Differential Equations Support
Nonlinear Optimization Problem Solvers
Support Functions
BLACS Routines
Data Fitting Functions
Appendix A: Linear Solvers Basics
Appendix B: Routine and Function Arguments
Appendix C: FFTW Interface to Intel® Math Kernel Library
Appendix D: Code Examples
Appendix F: oneMKL Functionality
Bibliography
Glossary
Notices and Disclaimers
mkl_?csrgemv
mkl_?bsrgemv
mkl_?coogemv
mkl_?diagemv
mkl_?csrsymv
mkl_?bsrsymv
mkl_?coosymv
mkl_?diasymv
mkl_?csrtrsv
mkl_?bsrtrsv
mkl_?cootrsv
mkl_?diatrsv
mkl_cspblas_?csrgemv
mkl_cspblas_?bsrgemv
mkl_cspblas_?coogemv
mkl_cspblas_?csrsymv
mkl_cspblas_?bsrsymv
mkl_cspblas_?coosymv
mkl_cspblas_?csrtrsv
mkl_cspblas_?bsrtrsv
mkl_cspblas_?cootrsv
mkl_?csrmv
mkl_?bsrmv
mkl_?cscmv
mkl_?coomv
mkl_?csrsv
mkl_?bsrsv
mkl_?cscsv
mkl_?coosv
mkl_?csrmm
mkl_?bsrmm
mkl_?cscmm
mkl_?coomm
mkl_?csrsm
mkl_?cscsm
mkl_?coosm
mkl_?bsrsm
mkl_?diamv
mkl_?skymv
mkl_?diasv
mkl_?skysv
mkl_?diamm
mkl_?skymm
mkl_?diasm
mkl_?skysm
mkl_?dnscsr
mkl_?csrcoo
mkl_?csrbsr
mkl_?csrcsc
mkl_?csrdia
mkl_?csrsky
mkl_?csradd
mkl_?csrmultcsr
mkl_?csrmultd
Naming Conventions in Inspector-Executor Sparse BLAS Routines
Sparse Matrix Storage Formats for Inspector-executor Sparse BLAS Routines
Supported Inspector-executor Sparse BLAS Operations
Two-stage Algorithm in Inspector-Executor Sparse BLAS Routines
Matrix Manipulation Routines
Inspector-Executor Sparse BLAS Analysis Routines
Inspector-Executor Sparse BLAS Execution Routines
mkl_sparse_?_create_csr
mkl_sparse_?_create_csc
mkl_sparse_?_create_coo
mkl_sparse_?_create_bsr
mkl_sparse_copy
mkl_sparse_destroy
mkl_sparse_convert_csr
mkl_sparse_convert_bsr
mkl_sparse_?_export_csr
mkl_sparse_?_export_csc
mkl_sparse_?_export_bsr
mkl_sparse_?_set_value
mkl_sparse_?_update_values
mkl_sparse_order
mkl_sparse_?_lu_smoother
mkl_sparse_?_mv
mkl_sparse_?_trsv
mkl_sparse_?_mm
mkl_sparse_?_trsm
mkl_sparse_?_add
mkl_sparse_spmm
mkl_sparse_?_spmmd
mkl_sparse_sp2m
mkl_sparse_?_sp2md
mkl_sparse_sypr
mkl_sparse_?_syprd
mkl_sparse_?_symgs
mkl_sparse_?_symgs_mv
mkl_sparse_syrk
mkl_sparse_?_syrkd
mkl_sparse_?_dotmv
mkl_sparse_?_sorv
cblas_?axpy_batch
cblas_?axpy_batch_strided
cblas_?axpby
cblas_?gemmt
cblas_?gemm3m
cblas_?gemm_batch
cblas_?gemm_batch_strided
cblas_?gemm3m_batch_strided
cblas_?gemm3m_batch
cblas_?trsm_batch
cblas_?trsm_batch_strided
mkl_?imatcopy
mkl_?imatcopy_batch
mkl_?imatcopy_batch_strided
mkl_?omatadd_batch_strided
mkl_?omatcopy
mkl_?omatcopy_batch
mkl_?omatcopy_batch_strided
mkl_?omatcopy2
mkl_?omatadd
cblas_?gemm_pack_get_size, cblas_gemm_*_pack_get_size
cblas_?gemm_pack
cblas_gemm_*_pack
cblas_?gemm_compute
cblas_gemm_*_compute
cblas_gemm_bf16bf16f32_compute
cblas_gemm_bf16bf16f32
cblas_gemm_f16f16f32_compute
cblas_gemm_f16f16f32
cblas_?gemm_free
cblas_gemm_*
cblas_?gemv_batch_strided
cblas_?gemv_batch
cblas_?dgmm_batch_strided
cblas_?dgmm_batch
mkl_jit_create_?gemm
mkl_jit_get_?gemm_ptr
mkl_jit_destroy
Choosing a LAPACK Routine
C Interface Conventions for LAPACK Routines
Matrix Layout for LAPACK Routines
Matrix Storage Schemes for LAPACK Routines
Mathematical Notation for LAPACK Routines
Error Analysis
LAPACK Linear Equation Routines
LAPACK Least Squares and Eigenvalue Problem Routines
LAPACK Auxiliary Routines
LAPACK Utility Functions and Routines
LAPACK Test Functions and Routines
Additional LAPACK Routines (Included for Compatibility with Netlib LAPACK)
Matrix Factorization: LAPACK Computational Routines
Solving Systems of Linear Equations: LAPACK Computational Routines
Estimating the Condition Number: LAPACK Computational Routines
Refining the Solution and Estimating Its Error: LAPACK Computational Routines
Matrix Inversion: LAPACK Computational Routines
Matrix Equilibration: LAPACK Computational Routines
?getrf
mkl_?getrfnp
mkl_?getrfnpi
?getrf2
?gbtrf
?gttrf
?dttrfb
?potrf
?potrf2
?pstrf
?pftrf
?pptrf
?pbtrf
?pttrf
?sytrf
?sytrf_aa
?sytrf_rook
?sytrf_rk
?hetrf
?hetrf_aa
?hetrf_rook
?hetrf_rk
?sptrf
?hptrf
mkl_?spffrt2, mkl_?spffrtx
Syntax
Include Files
Description
Input Parameters
Output Parameters
See Also
Orthogonal Factorizations: LAPACK Computational Routines
Singular Value Decomposition: LAPACK Computational Routines
Symmetric Eigenvalue Problems: LAPACK Computational Routines
Generalized Symmetric-Definite Eigenvalue Problems: LAPACK Computational Routines
Nonsymmetric Eigenvalue Problems: LAPACK Computational Routines
Generalized Nonsymmetric Eigenvalue Problems: LAPACK Computational Routines
Generalized Singular Value Decomposition: LAPACK Computational Routines
Cosine-Sine Decomposition: LAPACK Computational Routines
Linear Least Squares (LLS) Problems: LAPACK Driver Routines
Generalized Linear Least Squares (LLS) Problems: LAPACK Driver Routines
Symmetric Eigenvalue Problems: LAPACK Driver Routines
Nonsymmetric Eigenvalue Problems: LAPACK Driver Routines
Singular Value Decomposition: LAPACK Driver Routines
Cosine-Sine Decomposition: LAPACK Driver Routines
Generalized Symmetric Definite Eigenvalue Problems: LAPACK Driver Routines
Generalized Nonsymmetric Eigenvalue Problems: LAPACK Driver Routines
?lacgv
?lacrm
?syconv
?syr
i?max1
?sum1
?gelq2
?geqr2
?geqrt2
?geqrt3
?getf2
?lacn2
?lacpy
?lakf2
?lange
?lansy
?lanhe
?lantr
LAPACKE_set_nancheck
LAPACKE_get_nancheck
?lapmr
?lapmt
?lapy2
?lapy3
?laran
?larfb
?larfg
?larft
?larfx
?large
?larnd
?larnv
?laror
?larot
?lartgp
?lartgs
?lascl
?lasd0
?lasd1
?lasd2
?lasd3
?lasd4
?lasd5
?lasd6
?lasd7
?lasd8
?lasd9
?lasda
?lasdq
?lasdt
?laset
?lasrt
?laswp
?latm1
?latm2
?latm3
?latm5
?latm6
?latme
?latmr
?lauum
?syswapr
?heswapr
?sfrk
?hfrk
?tfsm
?tfttp
?tfttr
?tpqrt2
?tprfb
?tpttf
?tpttr
?trttf
?trttp
?lacp2
?larcm
mkl_?tppack
mkl_?tpunpack
Systems of Linear Equations: ScaLAPACK Computational Routines
Matrix Factorization: ScaLAPACK Computational Routines
Solving Systems of Linear Equations: ScaLAPACK Computational Routines
Estimating the Condition Number: ScaLAPACK Computational Routines
Refining the Solution and Estimating Its Error: ScaLAPACK Computational Routines
Matrix Inversion: ScaLAPACK Computational Routines
Matrix Equilibration: ScaLAPACK Computational Routines
Orthogonal Factorizations: ScaLAPACK Computational Routines
Symmetric Eigenvalue Problems: ScaLAPACK Computational Routines
Nonsymmetric Eigenvalue Problems: ScaLAPACK Computational Routines
Singular Value Decomposition: ScaLAPACK Driver Routines
Generalized Symmetric-Definite Eigenvalue Problems: ScaLAPACK Computational Routines
p?lacgv
p?max1
pilaver
pmpcol
pmpim2
?combamax1
p?sum1
p?dbtrsv
p?dttrsv
p?gebal
p?gebd2
p?gehd2
p?gelq2
p?geql2
p?geqr2
p?gerq2
p?getf2
p?labrd
p?lacon
p?laconsb
p?lacp2
p?lacp3
p?lacpy
p?laevswp
p?lahrd
p?laiect
p?lamve
p?lange
p?lanhs
p?lansy, p?lanhe
p?lantr
p?lapiv
p?lapv2
p?laqge
p?laqr0
p?laqr1
p?laqr2
p?laqr3
p?laqr5
p?laqsy
p?lared1d
p?lared2d
p?larf
p?larfb
p?larfc
p?larfg
p?larft
p?larz
p?larzb
p?larzc
p?larzt
p?lascl
p?lase2
p?laset
p?lasmsub
p?lasrt
p?lassq
p?laswp
p?latra
p?latrd
p?latrs
p?latrz
p?lauu2
p?lauum
p?lawil
p?org2l/p?ung2l
p?org2r/p?ung2r
p?orgl2/p?ungl2
p?orgr2/p?ungr2
p?orm2l/p?unm2l
p?orm2r/p?unm2r
p?orml2/p?unml2
p?ormr2/p?unmr2
p?pbtrsv
p?pttrsv
p?potf2
p?rot
p?rscl
p?sygs2/p?hegs2
p?sytd2/p?hetd2
p?trord
p?trsen
p?trti2
?lahqr2
?lamsh
?lapst
?laqr6
?lar1va
?laref
?larrb2
?larrd2
?larre2
?larre2a
?larrf2
?larrv2
?lasorte
?lasrt2
?stegr2
?stegr2a
?stegr2b
?stein2
?dbtf2
?dbtrf
?dttrf
?dttrsv
?pttrsv
?steqr2
?trmvt
pilaenv
pilaenvx
pjlaenv
Additional ScaLAPACK Routines
oneMKL PARDISO - Parallel Direct Sparse Solver Interface
Parallel Direct Sparse Solver for Clusters Interface
Direct Sparse Solver (DSS) Interface Routines
Iterative Sparse Solvers based on Reverse Communication Interface (RCI ISS)
Preconditioners based on Incomplete LU Factorization Technique
Sparse Matrix Checker Routines
pardiso
pardisoinit
pardiso_64
mkl_pardiso_pivot
pardiso_getdiag
pardiso_export
pardiso_handle_store
pardiso_handle_restore
pardiso_handle_delete
pardiso_handle_store_64
pardiso_handle_restore_64
pardiso_handle_delete_64
oneMKL PARDISO Parameters in Tabular Form
pardiso iparm Parameter
PARDISO_DATA_TYPE
vslNewStream
vslNewStreamEx
vsliNewAbstractStream
vsldNewAbstractStream
vslsNewAbstractStream
vslDeleteStream
vslCopyStream
vslCopyStreamState
vslSaveStreamF
vslLoadStreamF
vslSaveStreamM
vslLoadStreamM
vslGetStreamSize
vslLeapfrogStream
vslSkipAheadStream
vslSkipAheadStreamEx
vslGetStreamStateBrng
vslGetNumRegBrngs
Convolution and Correlation Naming Conventions
Convolution and Correlation Data Types
Convolution and Correlation Parameters
Convolution and Correlation Task Status and Error Reporting
Convolution and Correlation Task Constructors
Convolution and Correlation Task Editors
Task Execution Routines
Convolution and Correlation Task Destructors
Convolution and Correlation Task Copiers
Convolution and Correlation Usage Examples
Convolution and Correlation Mathematical Notation and Definitions
Convolution and Correlation Data Allocation
Summary Statistics Naming Conventions
Summary Statistics Data Types
Summary Statistics Parameters
Summary Statistics Task Status and Error Reporting
Summary Statistics Task Constructors
Summary Statistics Task Editors
Summary Statistics Task Computation Routines
Summary Statistics Task Destructor
Summary Statistics Usage Examples
Summary Statistics Mathematical Notation and Definitions
DFTI_PRECISION
DFTI_FORWARD_DOMAIN
DFTI_DIMENSION, DFTI_LENGTHS
DFTI_PLACEMENT
DFTI_FORWARD_SCALE, DFTI_BACKWARD_SCALE
DFTI_NUMBER_OF_USER_THREADS
DFTI_THREAD_LIMIT
DFTI_INPUT_STRIDES, DFTI_OUTPUT_STRIDES
DFTI_NUMBER_OF_TRANSFORMS
DFTI_INPUT_DISTANCE, DFTI_OUTPUT_DISTANCE
DFTI_COMPLEX_STORAGE, DFTI_REAL_STORAGE, DFTI_CONJUGATE_EVEN_STORAGE
DFTI_PACKED_FORMAT
DFTI_WORKSPACE
DFTI_COMMIT_STATUS
DFTI_ORDERING
DFTI_DESTROY_INPUT
Data Fitting Function Naming Conventions
Data Fitting Function Data Types
Mathematical Conventions for Data Fitting Functions
Data Fitting Usage Model
Data Fitting Usage Examples
Data Fitting Function Task Status and Error Reporting
Data Fitting Task Creation and Initialization Routines
Task Configuration Routines
Data Fitting Computational Routines
Data Fitting Task Destructors
DSS Symmetric Matrix Storage
DSS Nonsymmetric Matrix Storage
DSS Structurally Symmetric Matrix Storage
DSS Distributed Symmetric Matrix Storage
Sparse BLAS CSR Matrix Storage Format
Sparse BLAS CSC Matrix Storage Format
Sparse BLAS Coordinate Matrix Storage Format
Sparse BLAS Diagonal Matrix Storage Format
Sparse BLAS Skyline Matrix Storage Format
Sparse BLAS BSR Matrix Storage Format
Visible to Intel only — GUID: GUID-7C6574A1-164E-4A4A-A0F9-75949A5B35F7
mkl_?spffrt2, mkl_?spffrtx
Computes the partial LDLT factorization of a symmetric matrix using packed storage.
Syntax
void mkl_sspffrt2 (float *ap , const MKL_INT *n , const MKL_INT *ncolm , float *work , float *work2 );
void mkl_dspffrt2 (double *ap , const MKL_INT *n , const MKL_INT *ncolm , double *work , double *work2 );
void mkl_cspffrt2 (MKL_Complex8 *ap , const MKL_INT *n , const MKL_INT *ncolm , MKL_Complex8 *work , MKL_Complex8 *work2 );
void mkl_zspffrt2 (MKL_Complex16 *ap , const MKL_INT *n , const MKL_INT *ncolm , MKL_Complex16 *work , MKL_Complex16 *work2 );
void mkl_sspffrtx (float *ap , const MKL_INT *n , const MKL_INT *ncolm , float *work , float *work2 );
void mkl_dspffrtx (double *ap , const MKL_INT *n , const MKL_INT *ncolm , double *work , double *work2 );
void mkl_cspffrtx (MKL_Complex8 *ap , const MKL_INT *n , const MKL_INT *ncolm , MKL_Complex8 *work , MKL_Complex8 *work2 );
void mkl_zspffrtx (MKL_Complex16 *ap , const MKL_INT *n , const MKL_INT *ncolm , MKL_Complex16 *work , MKL_Complex16 *work2 );
Include Files
- mkl.h
Description
The routine computes the partial factorization A = LDLT , where L is a lower triangular matrix and D is a diagonal matrix.
CAUTION:
The routine assumes that the matrix A is factorizable. The routine does not perform pivoting and does not handle diagonal elements which are zero, which cause the routine to produce incorrect results without any indication.
Consider the matrix

, where a is the element in the first row and first column of A, b is a column vector of size n - 1 containing the elements from the second through n-th column of A, C is the lower-right square submatrix of A, and I is the identity matrix.
The mkl_?spffrt2 routine performs ncolm successive factorizations of the form

.
The mkl_?spffrtx routine performs ncolm successive factorizations of the form
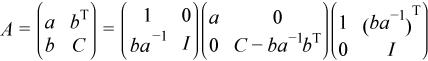
.
The approximate number of floating point operations performed by real flavors of these routines is (1/6)*ncolm*(2*ncolm2 - 6*ncolm*n + 3*ncolm + 6*n2 - 6*n + 7).
The approximate number of floating point operations performed by complex flavors of these routines is (1/3)*ncolm*(4*ncolm2 - 12*ncolm*n + 9*ncolm + 12*n2 - 18*n + 8).
Input Parameters
ap |
Array, size at least max(1, n(n+1)/2). The array ap contains the lower triangular part of the matrix A in packed storage (see Matrix Storage Schemes for uplo = 'L'). |
n |
The order of matrix A; n≥ 0. |
ncolm |
The number of columns to factor, ncolm≤n. |
work, work2 |
Workspace arrays, size of each at least n. |
Output Parameters
ap |
Overwritten by the factor L. The first ncolm diagonal elements of the input matrix A are replaced with the diagonal elements of D. The subdiagonal elements of the first ncolm columns are replaced with the corresponding elements of L. The rest of the input array is updated as indicated in the Description section.
NOTE:
Specifying ncolm = n results in complete factorization A = LDLT. |
Parent topic: Matrix Factorization: LAPACK Computational Routines